By estimating 3D shape and instances from a single view, we can capture information about an environment quickly, without the need for comprehensive scanning and multi-view fusion. Solving this task for composite scenes (such as object stacks) is challenging: occluded areas are not only ambiguous in shape but also in instance segmentation; multiple decompositions could be valid. We observe that physics constrains decomposition as well as shape in occluded regions and hypothesise that a latent space learned from scenes built under physics simulation can serve as a prior to better predict shape and instances in occluded regions. To this end we propose SIMstack, a depth-conditioned Variational Auto-Encoder (VAE), trained on a dataset of objects stacked under physics simulation. We formulate instance segmentation as a centre voting task which allows for class-agnostic detection and doesn't require setting the maximum number of objects in the scene. At test time, our model can generate 3D shape and instance segmentation from a single depth view, probabilistically sampling proposals for the occluded region from the learned latent space.
Towards fast object-level scene understanding with approximate reasoning for occluded regions
Shape reconstruction is important for scene understanding, estimating free space and can be useful for tracking,
but in order to allow for interactive tasks such as object manipulation, an object-level understanding of
the scene is crucial; this requires instance segmentation. With SIMstack we propose the first approach to
provide both 3D shape and instance decomposition for multiple (convex) stacked objects from a
single depth view. By providing class-agnostic
instance segmentation and training on scenes composed of primitive shapes (SuperQuadrics),
our approach is designed to work for unknown objects.
Our model reconstructs and segments the visible regions with high fidelity while generating shape and instance
proposals for occluded regions, conditioned on the visible information obtained from depth.
This allows for fast reconstruction and decomposition in the visible area and fast approximate object-level
reasoning for occluded areas.
Method
We learn a joint lower dimensional instance and shape encoding by training on a dataset of object stacks, generated under physics simulation. At test time, this learnt latent space is used within our depth-conditioned VAE to generate shape and instance decomposition in occluded regions. The extracted depth feature maps are used to generate accurate 3D shape for the visible region, while conditioning the generated 3D shape and instance decomposition of the entire stack.
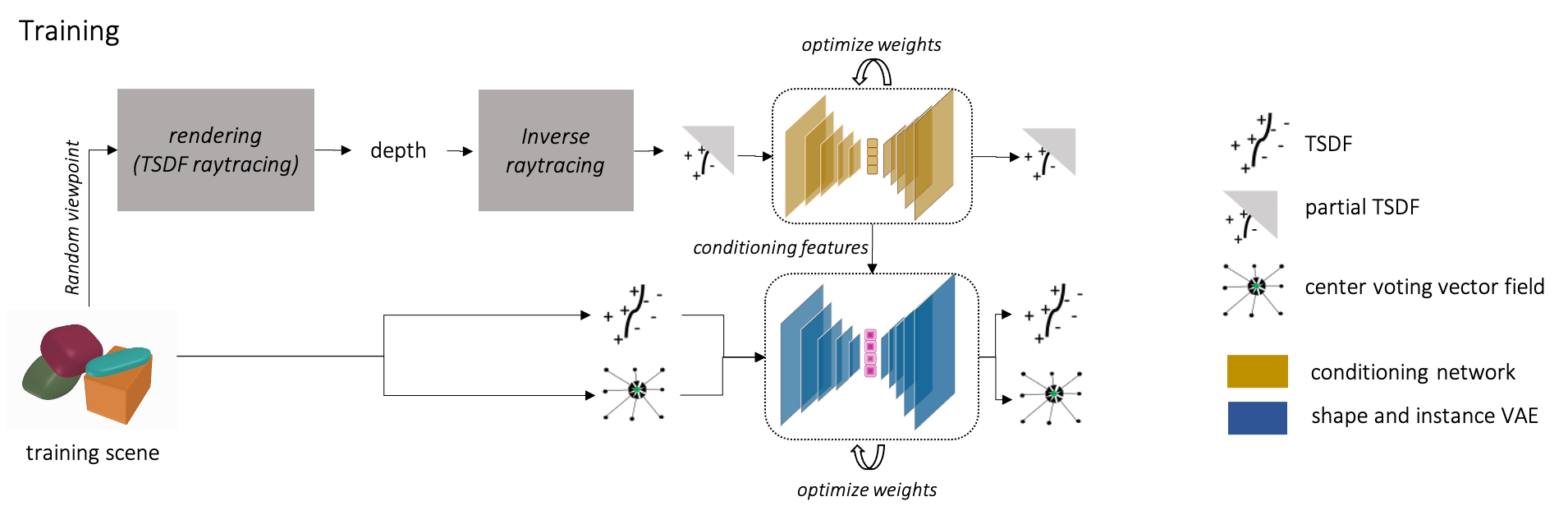
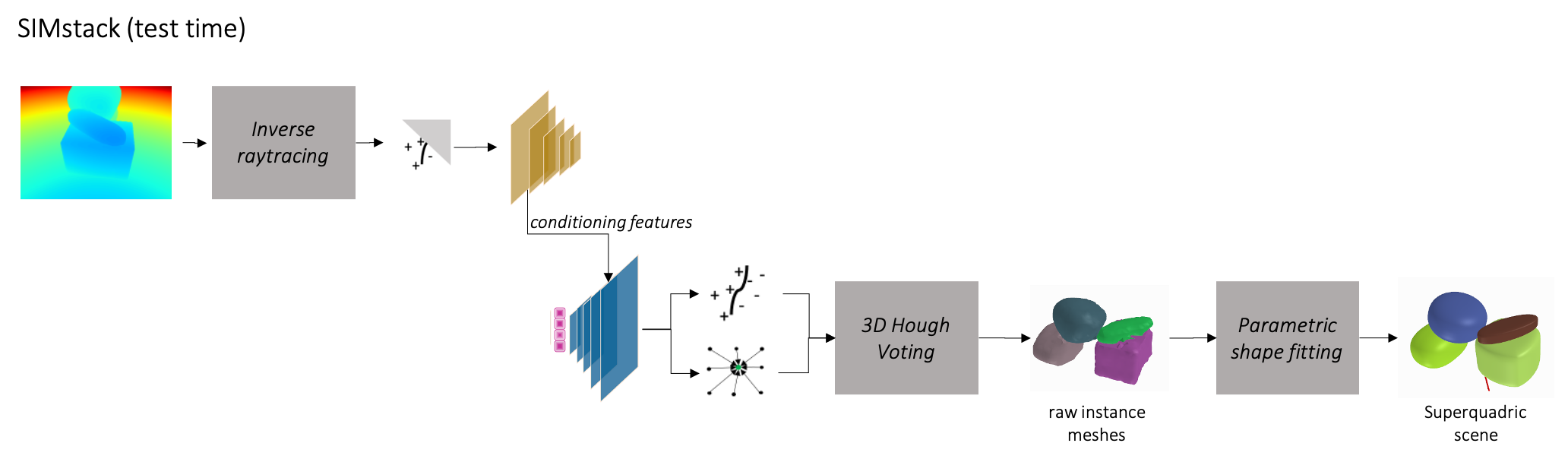
Results
We test SIMstack on scenes with up to 7 objects. Although our method is only trained on scenes with 3 to 4 objects, it generalises to more cluttered scenes.
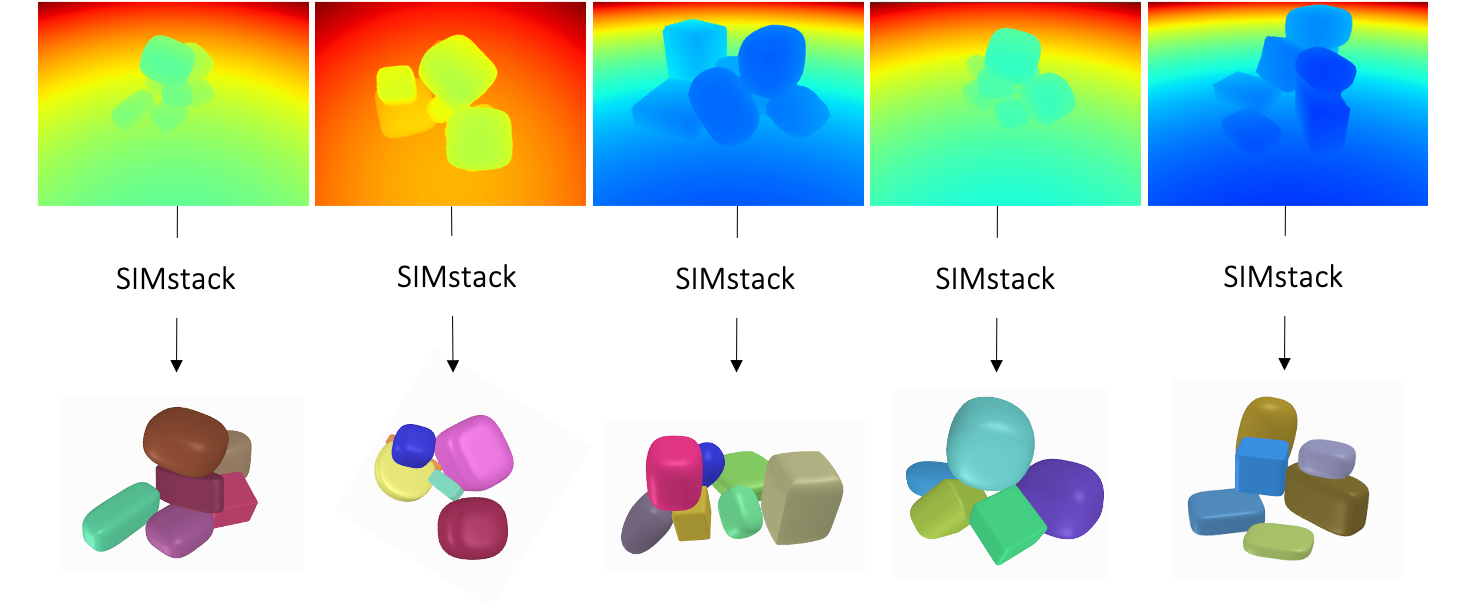
Our method can hypothetise fully occluded objects when generating 3D shape and instance segmentation. Sampling from the latent space produces different proposals of hidden objects
We test our method on a number of real world scenes of stacked objects. Our experiments show that SIMstack generalises well to real world data

Grasping Application
We demonstrate an application of SIMstack for an interactive task: non-disruptive and precise grasping. Given a real scene of a few stacked objects, we load the output of SIMstack into CoppeliaSIM and find the least disruptive grasp to remove a supporting target object. This demo shows the improtance of object-level scene understanding for interactive tasks.
Stability evaluation
We evaluate the validity of SIMstack's instance decomposition under physics simulation. The more stable the stack, the better (more realistic) the decomposition.